
Part I: Robots are reading receipts! And everything else you need to know about deep learning
If you’re new to machine learning, interested in working at a machine learning startup, or just want to know more about Sensibill’s tech, then this post is for you. In this two-part series, I’m going to break down how machine learning works, why Sensibill cares to use it to process receipts, and how it’s going to revolutionize banking.
Teaching a machine to read receipts is hard
Unstructured, data isn't of much use. Machine learning is a way to use algorithms and mathematical models to uncover complex patterns implicit in a set of data. Machines then use those patterns to figure out whether new data fits, or is similar enough to predict future outcomes. The kicker? They learn to do this on their own. At Sensibill, our team uses machine learning to extract unstructured text from receipts and return structured data in the form of a digital receipt. What we’re trying to do is teach machines to read receipts the same way humans do: identify items, the categories items belong to, the merchant, the subtotal, the total and so on.Why do we care to do this? Because receipts have a ton of invaluable customer data that can predict future purchases, travels, business ventures and even life transitions. This predictive facility helps banks personalize their services and offer their customers the financial products they need at the moment they need them. This might sound straightforward, but teaching machines to extract information like humans do is not an easy problem to solve. Text means something to humans, but not to the untrained machine.We had to teach the machine to essentially understand and decode symbols. Teach it characters, words, and phrases. To decipher what a string of letters represents. Like teaching it that the text “WK FRMS VNTG CHDDR” on a receipt is actually “Wyke Farms Vintage Cheddar”.Beyond just being able to identify an item based on a pattern of characters, we’re teaching our machine to understand that WK FRMS VNTG CHDDR is a grocery item, and more specifically, that it’s cheese, which is a dairy product, and so on. This is known as item categorization at a very granular level. In order to accomplish this, we need to teach our machine to understand the true identity of things.
Why would anyone care if a machine knows that VNTG CHDDR is cheese?

Have you ever forgotten the name of a book and tried to Google it, using whatever keywords you think describe the plot? Google will populate that search for you by understanding your intent and the contextual meaning of the words you’re searching.It works the same way with receipts. It means that the next time you’re racking your brain for the name of that cheese you bought that one time, you can just search “cheese” and every Camembert, Gouda, or Kraft Single that you’ve ever bought (or have a receipt for) will populate. Because the machine knows what the word “cheese” means. If you can appreciate how Google's semantic search works - or if you really love cheese - you can understand the value of this functionality.Taking it a step further, our machine can understand purchases in context. It looks across a broader data set (set of receipts) and notices that you only buy this expensive Vintage Cheddar every other Friday. It spots this biweekly pattern along with a spike in overall spend, and recognizes it as a pay-day splurge. Suddenly, the machine has generated an insight that’s far more interesting than your affinity for cheese - it’s beginning to understand your spending behaviour. This kind of data on spending behaviour feeds into customer profiles and motives. As you can imagine, this intel is critical for banks, whose business depends on how well they can understand and anticipate their customer’s financial needs.
Let’s break down machine learning and artificial neural networks
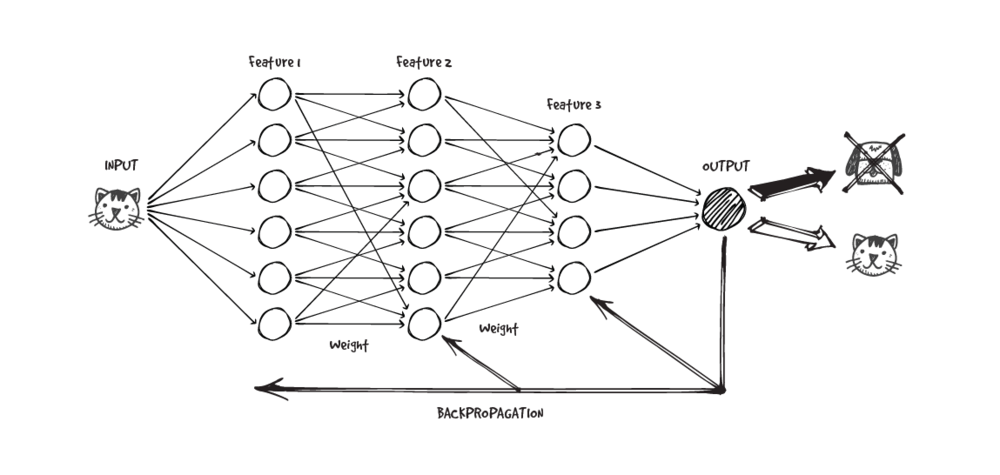
Humans have what feels like a natural ability to weave narratives about people based on very little information like a brick of cheese, but our cognitive capacities are really just a function of experience and time. Learning, by definition, is the transformative process of taking in information, internalizing it, and changing or building on what we know. It’s based on input, process and refinement. Our machine’s learning process is no different.Since our machine doesn’t have the luxury of a “natural experience” we have to supervise its learning. That means we provide our machine with the inputs (paper receipts), the outputs we expect (the itemized digital receipt), as well as corrections when the machine makes an error.We can compare this to a child learning how to classify animals. They see pictures of dogs (inputs) and start to build a classification based on certain features (process): 4 legs, a furry body, a tail etc. Next time they see an animal with these features, they call it a dog (output).With our machines, we provide the input - receipts from as broad a sample as we possibly can - to the artificial neural network (ANN) and compare the output the machine provides with the one we wanted. These receipts are called the training set. We then use an algorithm, called backpropagation, to learn the mapping function from the input to the output. The simplest way to understand this algorithm is to compare it to a child “learning from its mistakes”. If we go back to the dog classification example, we can imagine a young child mistaking a cat for a dog. It sees a cat, and says it’s a dog based on its classification: 4 legs, furry body, a tail. The child is corrected by its parents and informed that the animal is in fact a cat. The next time the child sees a cat, it is less likely to call it a dog. Similarly, any error our machine makes is corrected and fed back, "propagated", to the previous. In effect, this is the child going "back" and adjusting his classification of a dog. This process is repeated until the output error is below a predetermined threshold.In other words, we have to collect as many different receipts as possible in order to train our computer to read receipts really well. Once the algorithm is good enough, we have a "learned" artificial neural network, which is ready to process new inputs (new receipts). This artificial neural network is said to have learned from several examples (labeled receipts) and from its mistakes (error propagation).The aim is for the machine to be confident enough to give us a “safe answer” when it sees a receipt it has never seen before. This concept of understanding beyond the examples in the training set is known as generalization, and it’s the ultimate goal of machine learning.
So long, procedural programming. Hello, deep learning.
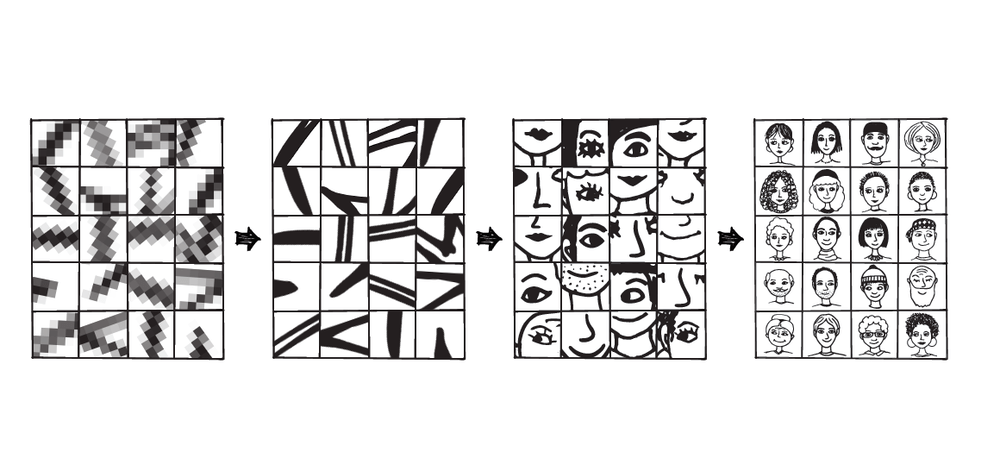
What I've just described is characteristic of a deep learning model. In order to understand the advantages of deep learning, I'd like to explain the disadvantages of past methods.Historically, the common approach was to feed computers with heuristics - or information and rules - specific to the subject studied, like say, a receipt. This required computer scientists to exhaustively write software that was only familiar with a receipt’s attributes, then rewriting and perfecting as the data or task changed. This procedural approach to programming was incredibly time-consuming and still left the system ill-equipped to deal with ambiguous data. In effect, the technology was limited by the input provided.Enter: deep learning. Deep learning is inspired by the mammalian visual cortex, which has a layered hierarchical architecture. Each layer identifies a certain pattern or feature, with successive layers identifying increasingly-higher level patterns or features. For example, the lower layers of the visual centres in the human brain correspond to primitive features such as lines of a particular orientation, corners, and edges. Once that layer accurately recognizes those features, they’re fed to higher layers, which are trained to recognize increasingly complex features, to form simple shapes like circles, squares, triangles. Repeating this process through multiple layers leads to the processing of higher level features, like being able to recognize someone's face.In deep learning, we try to mimic this multi-layered architecture so that we can learn directly from the raw input. When it comes to receipts, information is presented in a hierarchical fashion, starting with primitive features, like individual characters (a number, or a letter). Characters are then grouped together to form words that have simple patterns like a price. These simple patterns are then grouped together to form more complex patterns like an address. The process is repeated over and over until the system can produce a digital receipt and reliably recognize anything on the receipt. Imperfections in the text due to poor image quality is another challenge deep learning solves for. We know that our brains have an awesome ability to decode jumbled words, based on the brain’s ability to jump to conclusions when it sees a certain collection of letters. “S1M1L4RLY”, if we feed imperfect raw text to the machine, it will recognize certain patterns and learn to label the text correctly.Basically, with the deep learning approach, the machine will internally learn all the best heuristics necessary to accomplish a task. If this sounds oversimplified, that’s because it is. To really understand how our machines “internally” figure this out, you need to understand its neural network architecture: Recurrent Neural Networks (RNNs) using Long Short Term Memory (LSTM).
Continue to Part II, here.
If you're interested in working at Sensibill, peep our current job openings: https://www.linkedin.com/careersite/sensibill