
Part II: Robots are reading receipts! And everything else you need to know about deep learning
In Part 1 of this machine learning series, I explained how Sensibill is applying deep learning techniques to read and understand the information presented on a receipt. In Part 2, I'm going to cover the actual architecture of our machine and explain how Recurrent Neural Networks (RNNs) work. In particular, I want to introduce a type of RNN: Long-Short-Term Memory (LSTM).
The Gist of Recurrent Neural Networks
First, let’s recap. An artificial neural network is an interconnected group of nodes or neurons, similar to a network of neurons in a brain. Artificial Neural Networks (ANNs) can be classified into two categories, according to the direction of information flow:
Feedforward Neural Networks
Recurrent Neural Networks

Receipt Classification
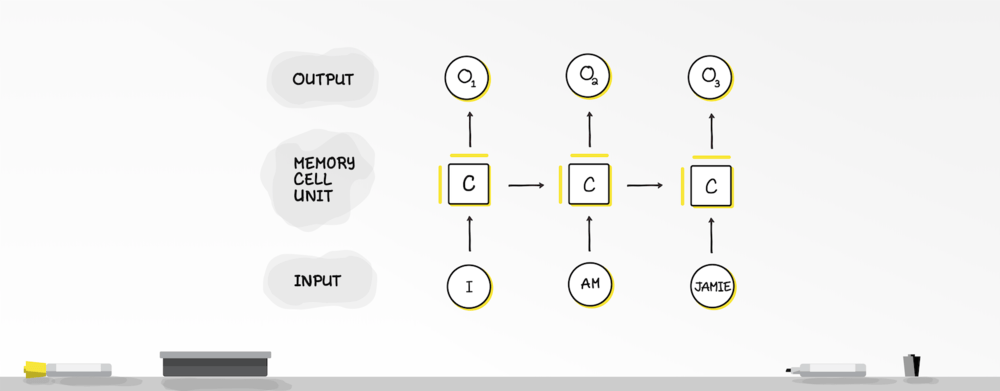
Recurrent Neural Network
Feedforward neural networks are "simple" nets. Information flows strictly forward – from the inputs, through to the outputs. Although feedforward networks have shown great potential for straightforward problems like image classification, they are lackluster when it comes to solving problems that require the network to “remember” information over time. In other words, a feedforward network can only learn to consider the current input it is exposed to, without any context of the past or the future. Most interesting problems require understanding something in context. For example, in order to understand what you’re reading right now, your brain needs to remember what it read one word earlier, and one word before that. And it needs to keep remembering those words as it continues to process new words. Previous information, or context, matters to us. Good robot! Bad robot! Reading a receipt may not be complicated per se, but it still requires us to understand basic sequential information. Characters on a receipt have no meaning in isolation.
The information is contained in the sequence itself - the string of digits and characters. A price has no meaning if it’s not attached to an item or a total. They’re just numbers. What we’re trying to do at Sensibill is train our machine to understand these patterns; basically, to learn the syntax of receipts. For everything presented on a receipt, we have a desired output: the right date, the time, the merchant name, products, SKUs, return date- you get the idea. Humans can take a look at a receipt and immediately process the relevant information and what it means. That’s because our brains are trained to recognize patterns in the whole sequence. All receipts are formatted similarly, so our brains instantly know where to find the merchant’s name, their address, the grand total, and so on. That is, our brain can instantly classify sequential information on a receipt, like so: Introducing “memory" to the net. Simple enough, right? Not exactly. How easily humans can classify sequential information is deceptive. We have millions of years of evolution on our side, with a million brain cells constantly firing to process, store and retrieve information. Teaching neural nets to process information in the same way as a human brain is not a simple task.
For starters, they don’t have our capacity to remember information. Our memory is critical to how we store, process, and understand content. That’s why we had to create a neural network with a “memory”. Enter: Recurrent Neural Networks. These networks, unlike feedforward nets, allow information to be passed recursively within the network. The sequential information on a receipt is preserved in the recurrent network’s hidden state, which can span many time steps as it cascades forward to affect the processing of each new input.
Just as our memory circulates our brain affecting our behavior unconsciously, sequential information circulates in the hidden states of recurrent nets affecting their output. Even though we can’t see what’s happening, the model is trying to learn how much each input contributes to the output as well as outputs in the future. But what happens if the gap between the relevant information we need and the output we want is big? Say, if we have an extremely long receipt and the information presented near the beginning of the receipt is important for understanding information that comes later on in the receipt. That is, it needs to remember “long-term dependencies”.
Vanishing gradients

Unrolled Recurrent Neural Network
Unfortunately, recurrent nets can’t always do this accurately. The most common challenge with RNNs is something called a vanishing gradient. (Nets can have exploding gradients as well, but these are traditionally easier to solve. For our task, we come across vanishing gradients more often so we will focus on those). The problem of vanishing gradients is that the network cannot be trained to remember information over a certain sequence length due to the mathematical and computational limitations of trying to remember all possible information over time.
Basically, it forgets relevant information that it had processed earlier on in a sequence, which impairs how it processes new information. How does this happen? Similar to feedforward nets, we use backpropagation of error to identify what’s responsible for producing an error in the output. Like I explained in Part 1, backpropagation is the training signal – going backward and adjusting weights of layers until the net output and the desired output are the same. But unlike feedforward nets, RNNs have loops that backpropagation must unroll through time. The longer the sequence – or the receipt, in our case – the more “loops” to unroll, making it exponentially harder to learn and tune earlier layers.LSTM: The elephant in the room And so, Long Short Term Memory Units (LSTMs) were born.
Drumroll, please. LSTMs are a special kind of RNN that remember long-term dependencies for as long as they’re needed. This is done through a method called gating. With gating, LSTMs have a secular unit capable of choosing what information should persist over time. For example, when you have a really long receipt, there’s some irrelevant information you don’t need to remember throughout to accomplish your task. If you’re trying to identify the items on a receipt, it’s not necessary to remember the date from the beginning of the receipt. Paying attention to some information, and less attention to other information helps you focus on the things you need to remember instead of remembering everything. LSTMs figure this out through learning as well. They learn what information is relevant and should be remembered, and what information is irrelevant and can be forgotten. This way, the mathematical and computational limitations for remembering information over time are lifted.
This way, our machine can effectively remember anything we need it to, for as long as we need it to until we no longer need to. To wrap it up we've learned about RNNs, how they work, and how we use them at Sensibill. We’ve also talked about their imperfect memory, the need for LSTM units to preserve relevant information over time, and that teaching a machine to read a receipt is no easy feat. The promises of artificial intelligence go far beyond the scope of receipts or even financial services as a whole. In particular, machine learning is transforming our capacity to process information, and ultimately, transforming commerce as we know it.
If I’ve whet your appetite for the topic, I highly recommend the following resources for more in-depth explanations:http://karpathy.github.io/2015/05/21/rnn-effectiveness/ http://colah.github.io/posts/2015-08-Understanding-LSTMs/https://deeplearning4j.org/lstm.html
* In an earlier version of this post, our receipt image incorrectly classified HST as "Total".